11 Doctors across the world: making maps with ggplot2
In this chapter we’ll learn how to identify open data sources, make maps with ggplot2 using data from the maps package, and create title panels with an unorthodox use of facets.
By the end of this chapter, you’ll be able to:
- Create a simple choropleth map using only functions available in the core
ggplot2package; - Obtain country boundary data and understand why coordinate systems matter for spatial data; and
- Manipulate plot elements in a
ggplot2chart to create a colored background area for the plot title.
We begin by loading the packages required in this chapter.
This package introduces another new package, MetBrewer, which is another color palette package, similar to rcartocolor introduced in Chapter 6. We also need to make sure the maps package is installed; although we don’t need to explicitly load it with library(), because we’ll be accessing it through ggplot2.
11.1 Data
We’ll visualize data on Medical doctors per 1,000 people using the dataset from the Our World in Data website (ourworldindata.org) (Our World in Data 2019) whose aim, according to their website, is to publish the research and data to make progress against the world’s largest problems. There are datasets on everything from energy and environment, to poverty and education, to name a few. Their website also has many examples of beautiful, effective data visualizations if you’re ever looking for inspiration.
You can either download the CSV file from ourworldindata.org/grapher/physicians-per-1000-people manually, or you can, as we did in Chapter 6, download it directly into R using the URL. Simply pass the URL into the read_csv() function from readr (or read.csv() from base R if you prefer). As in Chapter 6, we split the URL into the base URL and the specific page of interest to make it easier to later load in other datasets if we choose to.
The owidapi R package (Scheuch 2025) provides an R interface to the Our World in Data website, allowing you to search and download data in R without having to navigate through the website. However, it’s not much less complicated than passing in the URL to read_csv().
Previously, the owidR package (York 2023) also provided a similar interface, but at the time of writing, it hasn’t been updated to use the newest Our World in Data API which results in errors when accessing data.
You may choose to save a copy of doctors as a CSV file for later use by using write.csv() or write_csv() from readr. This means you don’t have to download the data each time you open R and don’t have to worry about the data updating when you’re halfway through your analysis. You can then later read in the data with read.csv or read_csv() from readr.
There’s often a Bring Your Own Data week each year of TidyTuesday (R4DS Online Learning Community 2023), where participants are encouraged to source their own data. Some use their own data - visualizing how many times they’ve gone for a run over the past year, or recreating GitHub contributions graphs. Others choose to find and visualize other sources of data. So where do you find publicly available data?
There are many open sources of data, covering a wide range of topics, time frames, and regions across the world. Some government organizations have data portals, some companies have APIs you can access, some academic papers have accompanying data, or the Google dataset search engine (datasetsearch.research.google.com) might also help you to identify data you’re interested in.
11.2 Exploratory work
Let’s start by exploring the data to see if there are interesting patterns that can be visualized.
11.2.1 Data exploration
The data is reasonably small, containing only 4 columns: Entity (denoting the country or a larger region), Code (the country code), Year (year the data relates to), and Physicians (per 1,000 people). The 4939 rows of data cover 222 different regions (some aggregates of others), with data covering 62 years.
head(doctors)# A tibble: 6 × 4
Entity Code Year `Physicians (per 1,000 people)`
<chr> <chr> <dbl> <dbl>
1 Afghanistan AFG 1960 0.035
2 Afghanistan AFG 1965 0.063
3 Afghanistan AFG 1970 0.065
4 Afghanistan AFG 1981 0.077
5 Afghanistan AFG 1986 0.183
6 Afghanistan AFG 1987 0.179Often when there’s a time component to data, one of the most obvious patterns to consider is how other variables change over time. Although line charts are probably most common for visualizing time series data, a simple scatter plot can also indicate if there’s a general trend in the data. Sometimes, scatter plots also look cleaner than line charts - a line for each region in this chart would very much look like a spaghetti chart as discussed in Chapter 3.
plot(
x = doctors$Year,
y = doctors$`Physicians (per 1,000 people)`,
xlab = "Year",
ylab = "Physicians per 1,000 people"
)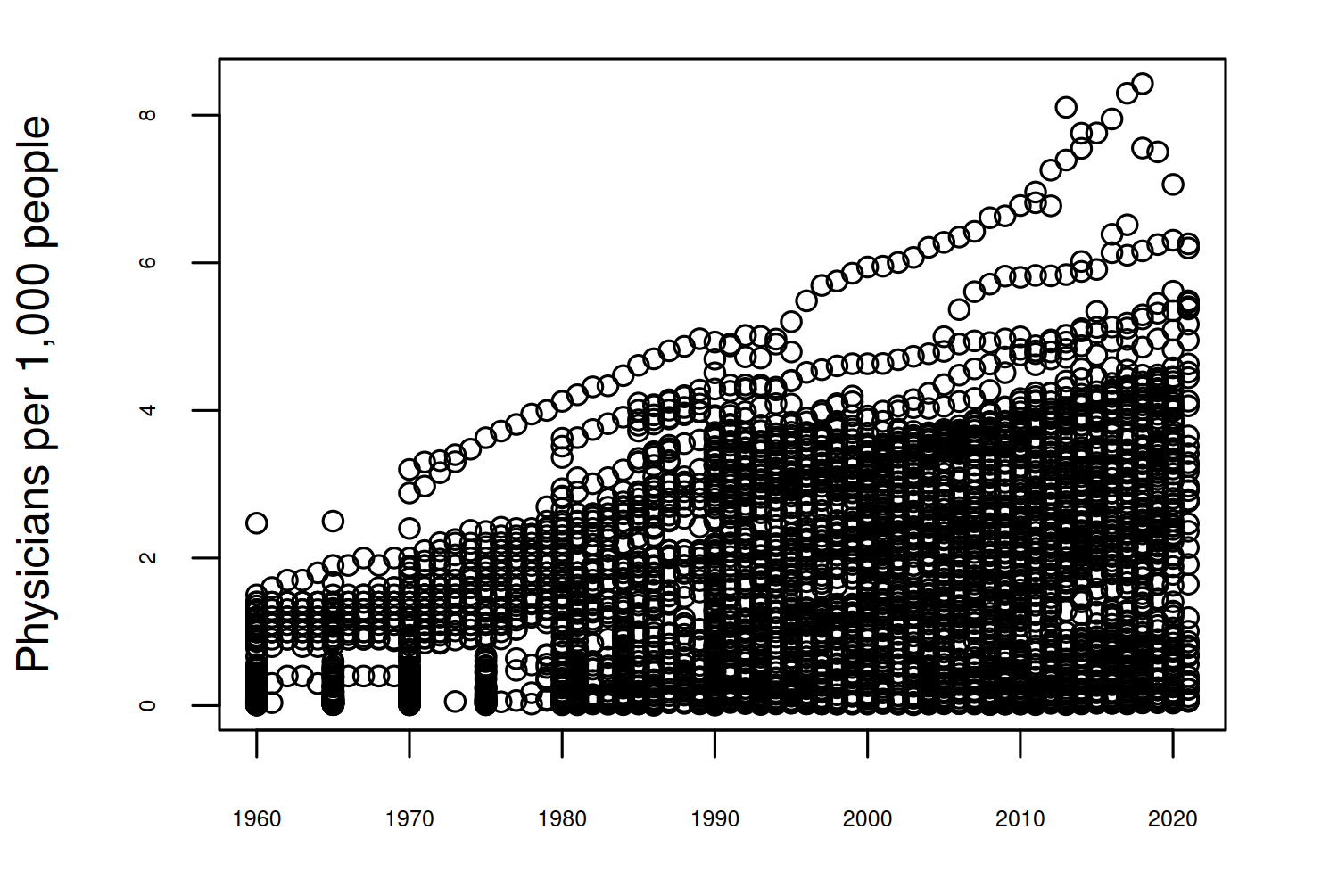
There seems to be a general increasing trend between 1960 and 2020 in Figure 11.1. The other important component of this data that we may want to explore is the spatial aspect - is there a pattern over space as well as over time?
11.2.2 Exploratory sketches
The most common approach to visualizing spatial data is, of course, to plot it on a map. If the aim is to show how a variable changes across different countries (or other defined regions), it’s very common to color the country based on the value of the variable. These are often termed choropleth maps.
At this point, it’s also often a good time to start thinking about the orientation and aspect ratio of the plot you’ll create. This will depend a lot on where the plot is going to end up - for example, plots in a single column academic article will typically be landscape graphs. The choice of orientation and aspect ratio can also affect how clearly your data is displayed - choosing a very wide plot for time series data can stretch the series and obliterate any appearance of trend. With maps, you’re a little bit more constrained because there is already an underlying aspect ratio in the plot you’re creating. For this map, a landscape orientation with a 6x4 aspect ratio should work reasonably well.
11.3 Preparing a plot
To create the map sketched out in Figure 11.2, we need to do two things (i) decide which data to plot, i.e., which regions and which years, and (ii) source some spatial data beyond just region names and country codes.
11.3.1 Data wrangling
Since this data is already fairly tidy, there isn’t too much data wrangling to be done. The only processing we really need to do is getting rid of the data we don’t need, and renaming a couple of columns to make them easier to work with. We can use the rename() function from dplyr to rename the Entity column to region (for reasons that will become clear in the next paragraph!). We also rename the Physicians (per 1,000 people) column to doctors to make it easier to work with, and rename Year to year for consistency. The data has multiple entries for each country, spanning different years. We could make an animated map to show how the number of doctors is changing over time, but for now we’ll keep it simple with a static map showing a snapshot at one point in time. However, there’s a bit of a problem. If you inspect the data, you’ll see that not every country has an entry for each year - let’s use the most recent data available for each country. For each region, we keep the row with only the most recent year using a combination of group_by() and slice_max() from {dplyr}.
To plot this data on a world map, we also need data for the country borders. Luckily, the map_data() function built into ggplot2 can help us with that! This function takes data from the maps package and turns it into an object you can plot directly with ggplot2.
world <- map_data("world")Of course, it’s never quite that straightforward. We need to join the world map data to our doctors data, and to do that, we need a column in each dataset to join by - we’ll use the region column. If you try to join these two datasets using the region column, you’ll notice that you end up with some unexpected NA values. So what’s going on?
You don’t need to rename columns in your data to be able to join them, but you may find it easier to work with the data after renaming Entity to region to maintain consistency across datasets.
There are two issues here. Firstly, there are more regions in the world data than there are in the doctors data:
This is partly due to the fact that the doctors data has implicitly missing values - if no data is available for a region, no rows exist in the data for that region. It isn’t listed with NA values. Note that there are also some regions in doctors which do not exist in world - for example, the entity "Upper-middle-income countries" is listed within doctors.
Secondly, if you inspect the region names, you’ll see that for some countries, their names are encoded differently. For example, in the world data, the United States is listed as "USA", while in the doctors data, it’s listed as "United States". Here, the easiest thing to do is manually rename the values that differ in one of the datasets. We can use the recode() function from dplyr to do that. Note that recode() has the rather unusual (for the tidyverse) syntax of old_name = new_name:
The entries in the region column of doctors that don’t correspond to countries, e.g., "Upper-middle-income countries" are not values that are required for the map. Therefore, a left_join() can be performed, with world on the left - keeping all the countries listed in world and joining only those with a corresponding value in doctors. The remaining countries in world with no match in doctors are listed with NA values. The rows for "Antarctica" are filtered out - Antarctica is often given a disproportionate amount of space on world maps (at least those not centered on Antarctica) in the process of projecting a sphere onto a rectangle.
Now, we have everything we need to create a simple map.
11.3.2 First plot
We start, as almost always, with the ggplot() function, and pass in the data and aesthetic mappings that will apply to the whole plot. The longitude (long) and latitude (lat) are passed to the x and y axes; and we specify that the fill color of each country should be based on the doctors column. We also specify map_id - an aesthetic mapping that isn’t seen as often as the others. This is used to tell geom_map() which column defines each region polygon (not entirely unlike the group aesthetic). Then, we use geom_map() to actually draw the map.
geom_map()
Both geom_sf() and geom_polygon() can be used as an alternative to geom_map() for creating maps within ggplot2.
However, they expect different formats of data. The geom_sf() function expects an sf object, in contrast to geom_map() which works with coordinates as columns in a data.frame or tibble. For examples of using geom_sf(), see Chapter 12.
You could also use geom_polygon() to plot map_data instead of geom_map(), but it makes it more difficult to project the map in the way we want to.
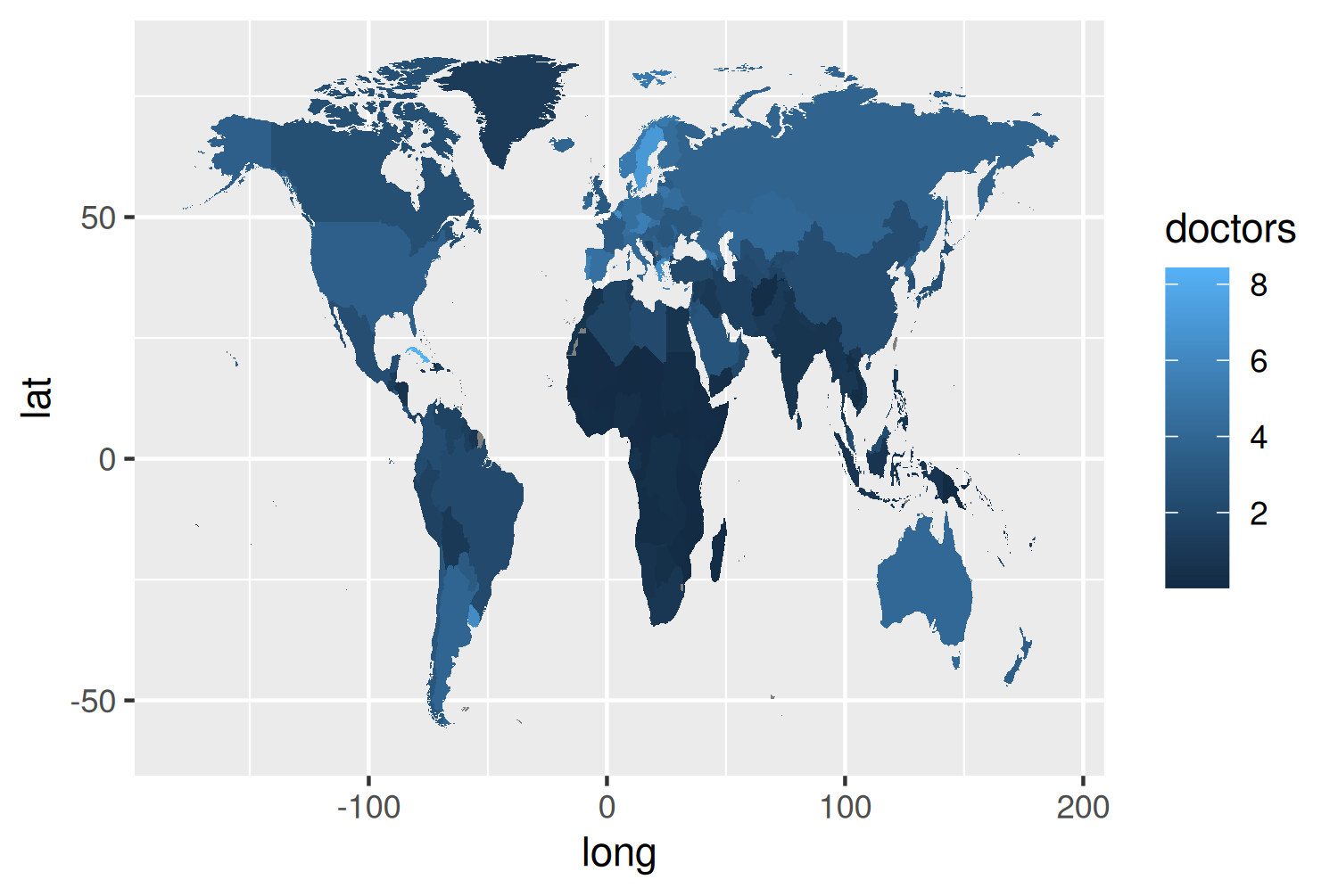
We now have a simple map in Figure 11.3 that shows our data, but there are several problems with it:
- The map looks as if someone has stretched it vertically, since there’s no map projection specified. Countries are still recognizable, but do not have quite the right shape.
- The color palette is not ideal. It’s more intuitive for brighter or lighter colors to represent smaller values, and for darker colors to represent higher values - at least for light-colored backgrounds (Schloss et al. 2019). The default gradient color scale in
ggplot2is the opposite way around. - There are labels that don’t need to be there (
latandlong), and missing labels that should be there (titleandsubtitle, for example).
So let’s fix those elements of the initial plot.
11.4 Advanced styling
We’ll start by considering alternative color palettes, then think about what text should be added, before finalizing the layout.
11.4.1 Colors
There are many, many color palette R packages in existence, and even more outside of the R ecosystem. In fact, the paletteer package (Hvitfeldt 2021) is designed to give a common interface to a comprehensive collection of color palettes in R. A popular color palette R package is MetBrewer (Mills 2022) - a collection of color palettes inspired by works of art at the Metropolitan Museum of Art in New York. It has many beautiful palettes, and many that work in traditional data visualizations. You can view all available palettes using display_all(colorblind_only = TRUE). Since doctors is a continuous variable, we’ll look at the sequential palettes only.
MetBrewer does have functions that interface directly with ggplot2 (such as scale_fill_met_c()), but we’re going to use some of the colors in the palette to also define variables for the highlight and text colors. To get a good range of colors, we extract 20 colors from the "Hokusai2" palette. The text_col is the 18th color and highlight_col is the 15th color. A variable containing the background color, bg_col, is also defined.
library(MetBrewer)
col_palette <- met.brewer("Hokusai2", n = 20)
text_col <- col_palette[18]
highlight_col <- col_palette[15]
bg_col <- "#EADEDA"These colors can then be passed into scale_fill_gradientn() from ggplot2. The limits of the color scale can also be set. Rather than adding labels for values on the legend, we can add text labels for Fewer doctors and More doctors. These are positioned 0.8 from the limits of the color scale in Figure 11.4.
col_plot <- basic_plot +
scale_fill_gradientn(
colors = col_palette,
limits = c(0, 10),
breaks = c(0.8, 9.2),
labels = c("Fewer doctors", "More doctors")
)
col_plot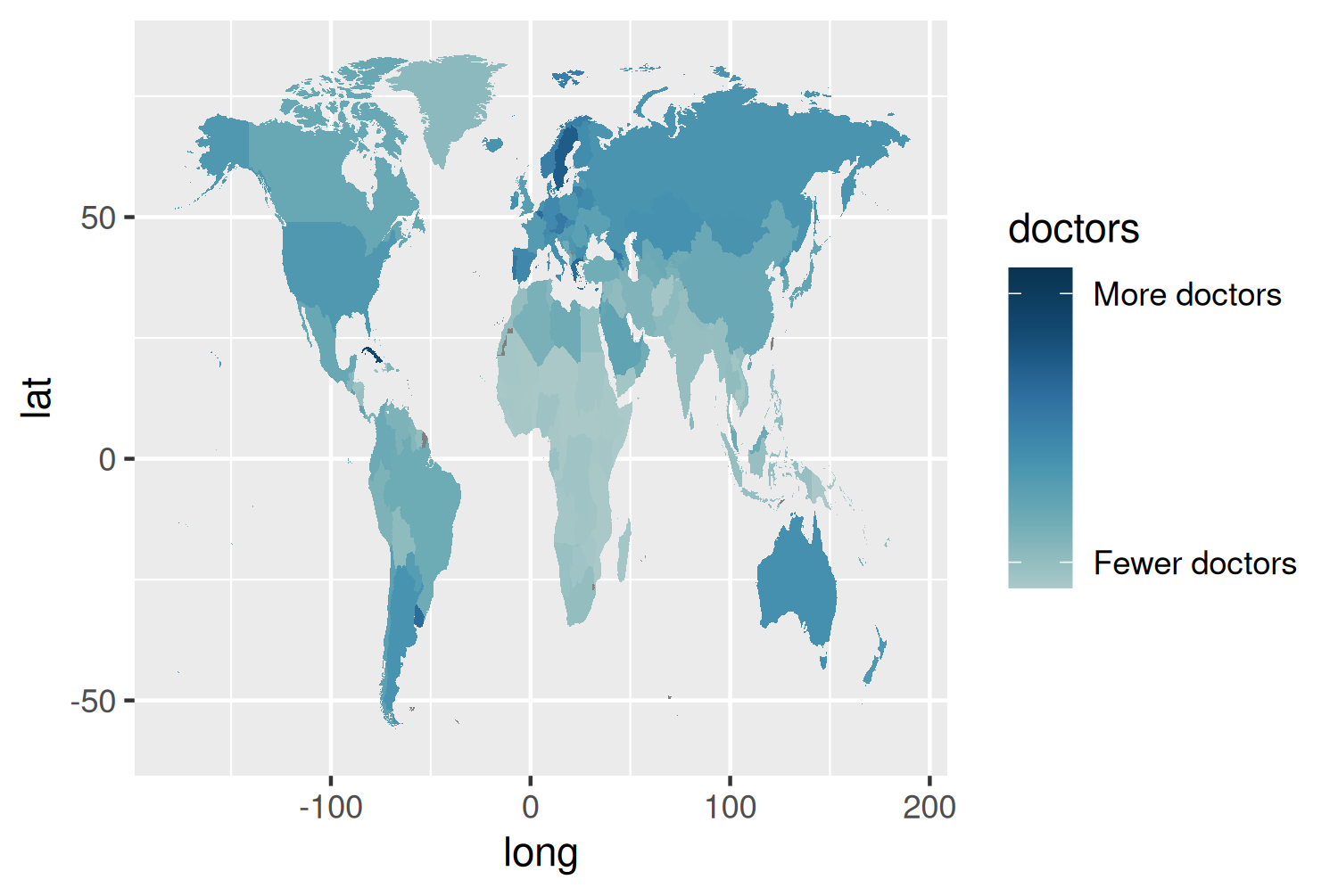
11.4.2 Text and fonts
As in previous chapters, fonts can be defined using the sysfonts and showtext packages. Here, the Roboto typeface is loaded through Google Fonts for the main font used, and Roboto Slab is loaded for use in the title.
font_add_google(name = "Roboto")
font_add_google(name = "Roboto Slab")
showtext_auto()
showtext_opts(dpi = 300)
body_font <- "Roboto"
title_font <- "Roboto Slab"Now, we can define some text for the title, subtitle, and caption. As in previous chapters, we’ll be using ggtext for formatting, which means we can use HTML syntax to add line breaks.
title <- "Doctors across the world"
subtitle <- "This map shows the number of doctors per thousand people, revealing which countries* may be more likely to struggle in providing care for a population.<br><br>*using the most recent available data for each country."Let’s create a custom caption that includes Font Awesome icons, as described in Chapter 7, which is passed into the source_caption() function we defined in Chapter 6:
social <- social_caption(
icon_color = highlight_col,
font_color = text_col,
font_family = body_font
)
caption <- source_caption(
source = "Our World in Data",
sep = "<br>",
graphic = social
)These text variables can then be passed into the labs() function.
text_plot <- col_plot +
labs(
title = title,
subtitle = subtitle,
caption = caption
)To apply our chosen typefaces to the plot, the theme elements need to be adjusted.
11.4.3 Adjusting themes
We start by adding theme_void() from ggplot2. The theme_void function removes all theme elements - including grid lines, axis labels, and the background. The legend and specified titles and subtitles remain. This theme is especially useful for maps where it’s more common for axis lines, axis titles, and grid lines not to be displayed. Like other built-in theme options, we can still set the base_size and base_family to set the default size and typeface for any text that is displayed.
We also set the plot.title, plot.subtitle, and plot.caption to use element_textbox_simple from ggtext to allow the markdown syntax and automatically wrap long subtitles in Figure 11.5, as we’ve seen in previous chapters.
text_plot +
theme_void(base_size = 8, base_family = body_font) +
theme(
plot.margin = margin(10, 10, 10, 10),
plot.background = element_rect(
fill = bg_col, color = bg_col
),
panel.background = element_rect(
fill = bg_col, color = bg_col
),
plot.title = element_textbox_simple(
color = text_col,
family = title_font
),
plot.subtitle = element_textbox_simple(
color = text_col
),
plot.caption = element_textbox_simple(
hjust = 0,
color = text_col
)
)
One of the aesthetic design choices we might want to make here, is to include the title within a banner with a different colored background. Although this might seem like a fairly straightforward thing to want, it’s actually not that easy with ggplot2. There are some solutions to the problem using packages like cowplot (Wilke 2024) or grid (R Core Team 2024) to draw rectangles and text. But we can do this within ggplot2 by using facets in a way they were not designed to be used. Let’s start by adding an additional column called label to map_data that contains the title (for every row in the data):
map_data$label <- titleThis column does not need to be called label, you can use any name you choose as long as it’s not an existing column.
You could also pass the title directly into facet_wrap() instead of creating a new column:
facet_wrap(~"Doctors across the world")Then we can use facet_wrap() and facet across the label column. Since there’s only one value of label in the data, this just adds the title as strip text at the top of the plot. While we’re here, let’s make the country outlines in the map the same color as the background and make the lines a little bit thicker.
styled_plot <- ggplot(
data = map_data,
mapping = aes(
long,
lat,
map_id = region,
fill = doctors
)
) +
geom_map(
map = map_data,
color = bg_col,
linewidth = 0.3
) +
scale_fill_gradientn(
colors = col_palette,
limits = c(0, 10),
breaks = c(0.8, 9.2),
labels = c("Fewer doctors", "More doctors")
) +
labs(
title = title,
subtitle = subtitle,
caption = caption
) +
facet_wrap(~label) +
theme_void(base_size = 7, base_family = body_font) +
theme(
plot.margin = margin(10, 10, 10, 10),
plot.background = element_rect(
fill = bg_col, color = bg_col
),
panel.background = element_rect(
fill = bg_col, color = bg_col
),
plot.title = element_textbox_simple(
color = text_col,
family = title_font,
lineheight = 0.5
),
plot.subtitle = element_textbox_simple(
color = text_col,
lineheight = 0.5
),
plot.caption = element_textbox_simple(
hjust = 0,
color = text_col,
lineheight = 0.5
),
strip.background = element_rect(
fill = highlight_col, color = highlight_col
)
)
styled_plot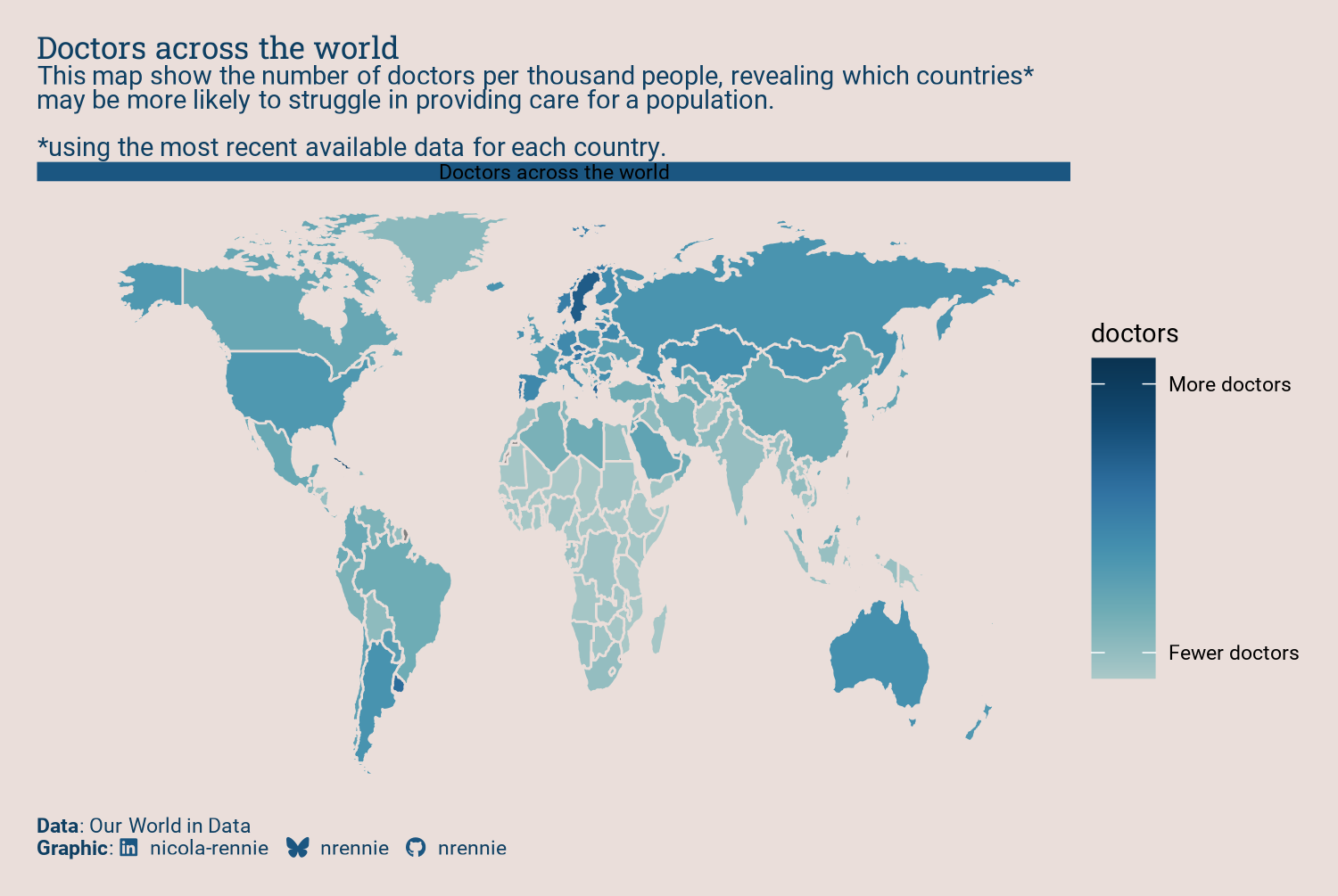
It’s obvious that there are some issues with Figure 11.6 now that the strip text contains the title:
- There is a duplicate title set using
labs(), and thestrip.texttitle is too dark to read against the blue background. - The subtitle is above the title.
- The map still appears stretched.
- The legend is taking up quite a lot of space, and the white ticks in the colorbar are distracting.
To solve the first two problems, the title and subtitle arguments of labs() can be set to NULL to remove them from the plot. Instead, the tag argument in labs() can be used to set the subtitle. The nice thing about using tag is the plot.tag.position argument within theme() which allows you to position the text anywhere on the plot. The strip.text and plot.tag arguments of theme should also be set using element_textbox_simple() from ggtext to allow the text to be styled as we wish. The top, left, and right margins of the plot should be set to 0 using plot.margin to make sure that the strip text banner goes to the edge of the plot.
To solve the third problem of the map looking stretched, we can apply coord_sf() which applies the World Geodetic System 1984 (WGS84) CRS (coordinate reference system). Chapter 12 discusses coordinate reference systems in more detail. The upper limit of the y-axis can also be extended beyond the range of the data to make room for the subtitle added using tag.
styled_plot2 <- styled_plot +
labs(
title = NULL, subtitle = NULL, tag = subtitle
) +
# add space for the tag (subtitle) text
coord_sf(ylim = c(-60, 140)) +
theme(
# move and format the tag (subtitle) text
plot.margin = margin(0, 0, 5, 0),
plot.tag.position = c(0.015, 0.8),
plot.tag = element_textbox_simple(
color = text_col,
lineheight = 0.6,
hjust = 0,
maxwidth = 0.98
),
# add margin for caption
plot.caption = element_textbox_simple(
hjust = 0,
color = text_col,
margin = margin(l = 5),
lineheight = 0.6
),
# change title text color
strip.text = element_textbox_simple(
color = bg_col,
family = title_font,
margin = margin(7, 5, 7, 5),
lineheight = 0.6,
size = rel(1.7)
)
)Note that the values used in plot.tag.position = c(0.015, 0.8) and the strip.text argument margin = margin(7, 5, 7, 5) took a lot of trial and error to get just right. There’s no magic involved in choosing these values!
To solve the final problem of the legend appearance, we can edit the style elements in theme. The legend.title is removed by setting it to a blank element with element_blank(), and the legend text labels are styled with element_text().
The placement of the legend is set through the legend.position, legend.justification.bottom, legend.margin, and legend.direction arguments.
ggplot2
Since version 3.5.0 of ggplot2, you can also style the theme of individual legends from inside the guide_*() functions. Prior to version 3.5.0, legend.position was used to position the legend inside the plot before legend.position.inside and legend.justification.bottom were introduced to allow custom legend positions more easily.
The other difference is that legend.ticks = element_blank() can be used to remove the white tick marks inside the colorbar legend. In older versions of ggplot2, guides(fill = guide_colorbar(ticks = FALSE)) would be used instead.
The size of the legend is controlled through the legend.key.width and legend.key.height arguments.
styled_plot2 +
theme(
# legend text
legend.title = element_blank(),
legend.text = element_text(
color = text_col,
lineheight = 0.5,
hjust = 0.5
),
# legend size
legend.key.width = unit(1.5, "cm"),
legend.key.height = unit(0.3, "cm"),
# legend position
legend.position = "bottom",
legend.justification.bottom = "right",
legend.margin = margin(-5, 5, 0, 0),
legend.direction = "horizontal",
legend.ticks = element_blank()
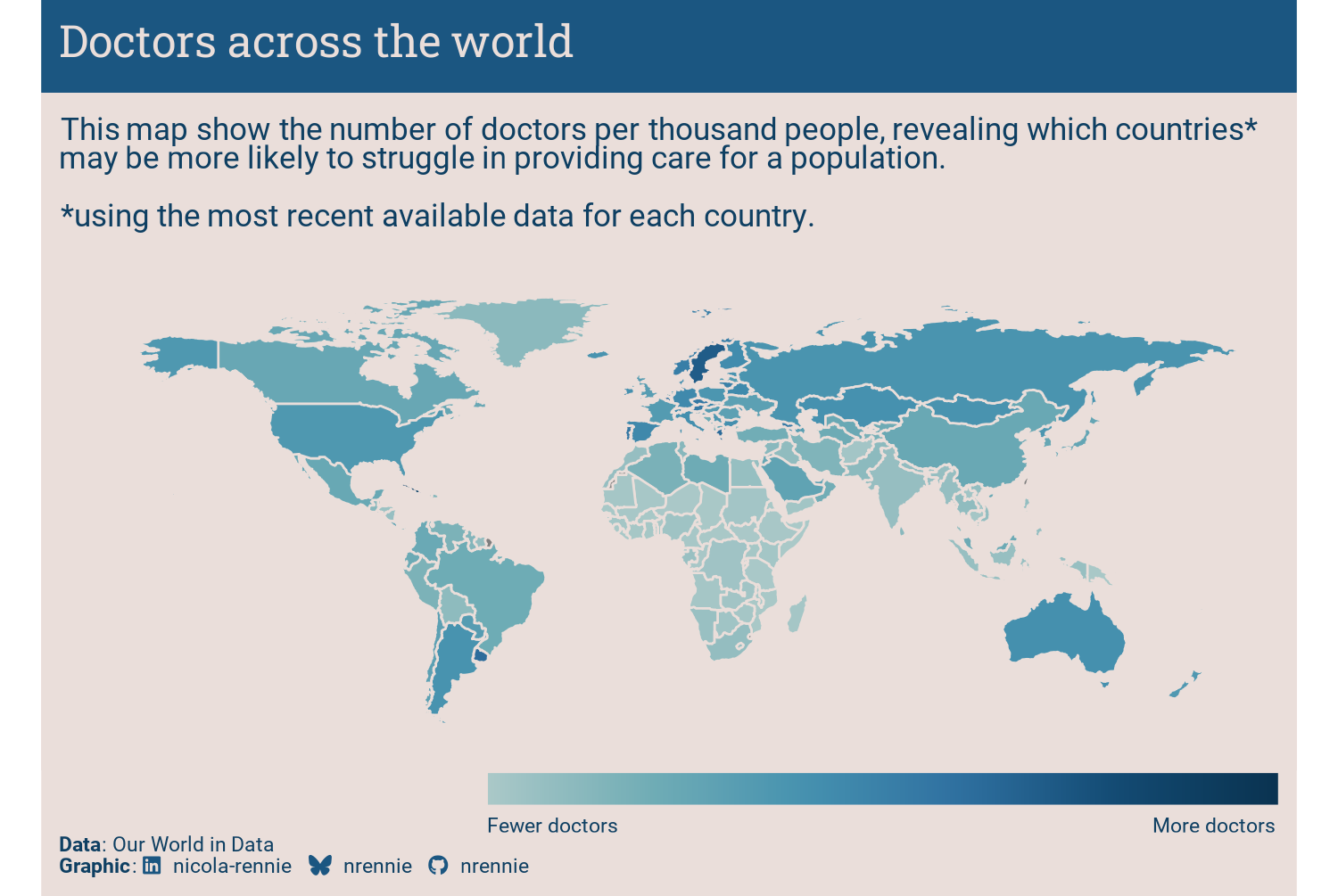
)
We can then finally save a copy with ggsave():
ggsave(
filename = "doctors.png",
width = 5,
height = 0.67 * 5
)11.5 Reflection
The color scale in Figure 11.7 is quite hard to interpret and the choice was made to use Fewer doctors and More doctors labels instead of values. When the underlying data is simple and easy to interpret, having the values on the legend would add more useful information. The title could probably also be changed to something more informative.
When the data was processed, the choice was made to plot a map showing the values for the most recently available data. This means that for some countries the data is more recent (and therefore perhaps more reliable), while for others it’s much older. In fact, running range(doctors$year) shows that the most recent data in the plot is from 2019, while the oldest is from 1980 - a gap of almost 40 years! That makes it much harder to accurately compare between countries, and there’s no indication for each country on this map how recent the data is. Readers might end up drawing conclusions that show differences between countries, when actually the difference is between time periods. Showing uncertainty on maps is tricky, and there’s no straightforward solution here. Perhaps one approach is setting the colors to a binary scale showing whether the value is above or below average, with the intensity of the color denoting the recentness of the data. The Vizumap package (Lucchesi and Kuhnert 2020), which provides functions for visualizing uncertainty on maps, could be used to create a bivariate map showing both the value and how recent it is. Or at least a more detailed explanation about the range of time the data relates to could be included within the subtitle.
Each plot created during the process of developing the original version of this visualization was captured using camcorder, and is shown in the gif below. If you’d like to learn more about how camcorder can be used in the data visualization process, see Section 14.1.
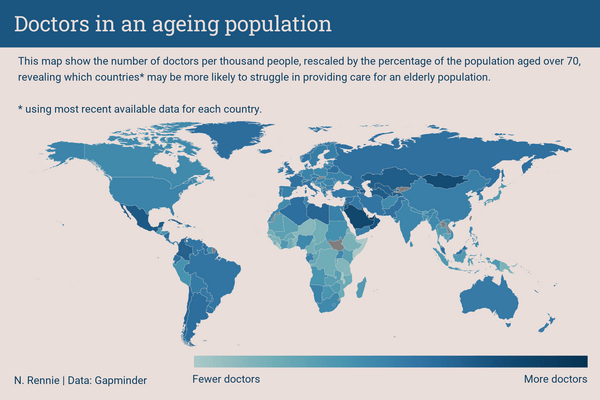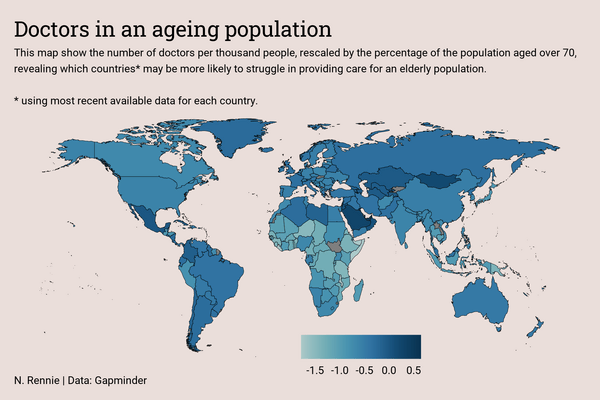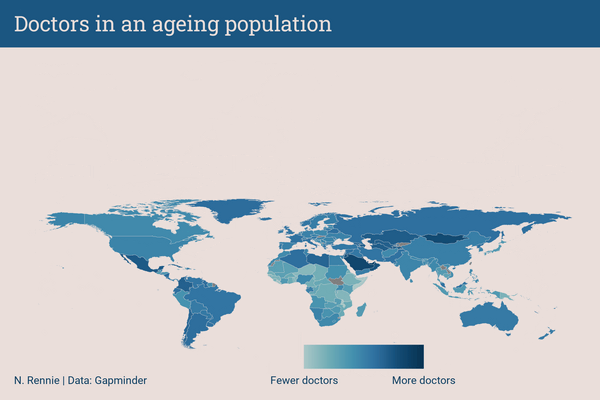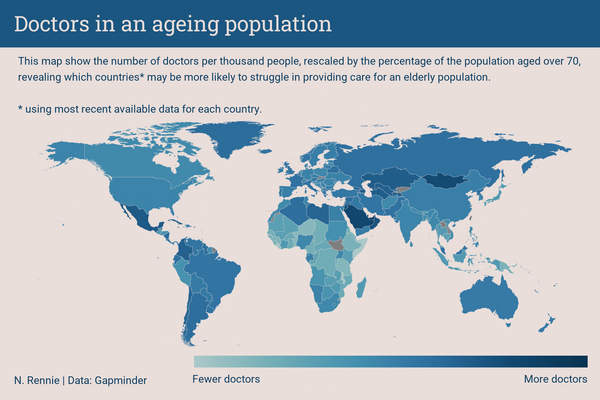
11.6 Exercises
Subset the data to create a map for only the following regions:
c("France", "Spain", "Italy", "Portugal", "Switzerland"). Do you need to change the limits of the x and y axes?Can you keep the countries that border these regions on the map but fill them with a neutral gray color?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}