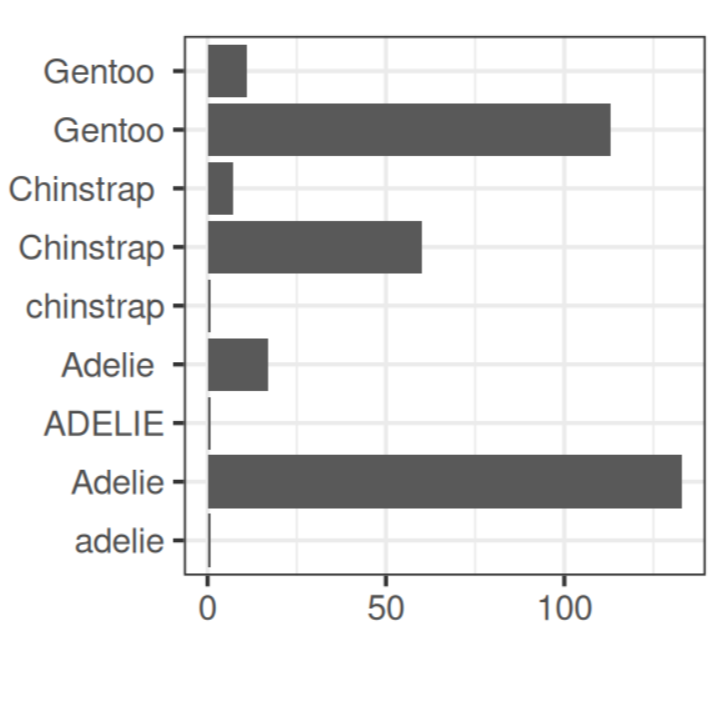
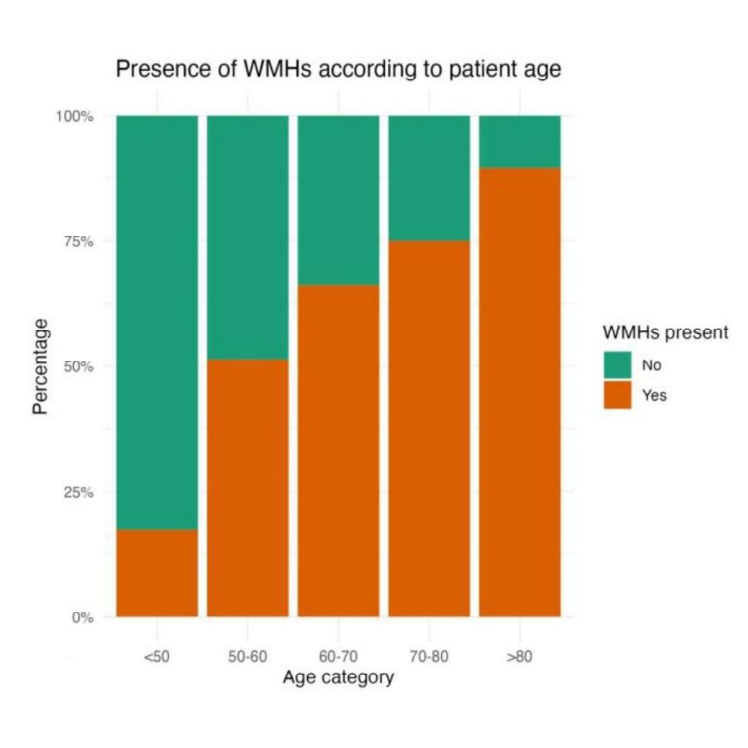
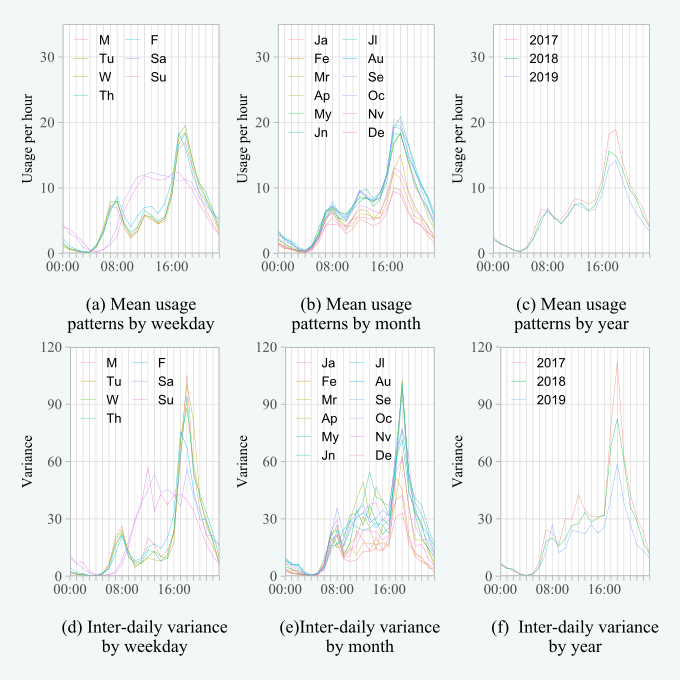
Published and submitted academic publications, and links to further blog posts.
Developing tools and techniques to improve the teaching of statistics, particularly statistical programming.
Different projects with applications in healthcare and medicine including neurology, reproductive healthcare, and the NHS workforce.
Developing statistical methodology to identify outliers in transport demand, with applications to railway and bike-sharing networks.