Physical Exercise in Patients with Subacute Stroke (PHYS-STROKE) Data
Physical Exercise in Patients with Subacute Stroke (PHYS-STROKE): safety analyses of six-month follow-up of a randomized clinical trial. Data set. Torsten Rackoll. 2020. doi.org/10.5281/zenodo.3899830
Perform the initial split (choose your own proportion!)
Create some cross-validation folds
Build a recipe and workflow
Solution
# Load R packages ---------------------------------------------------------library(tidyverse)library(tidymodels)tidymodels_prefer()# Load the `exercise.csv` data --------------------------------------------exercise <-read_csv("data/exercise.csv")exercise <- exercise |>mutate(SAE =factor(SAE))# Inspect variables -------------------------------------------------------barplot(table(exercise$SAE))
barplot(table(exercise$Gender))
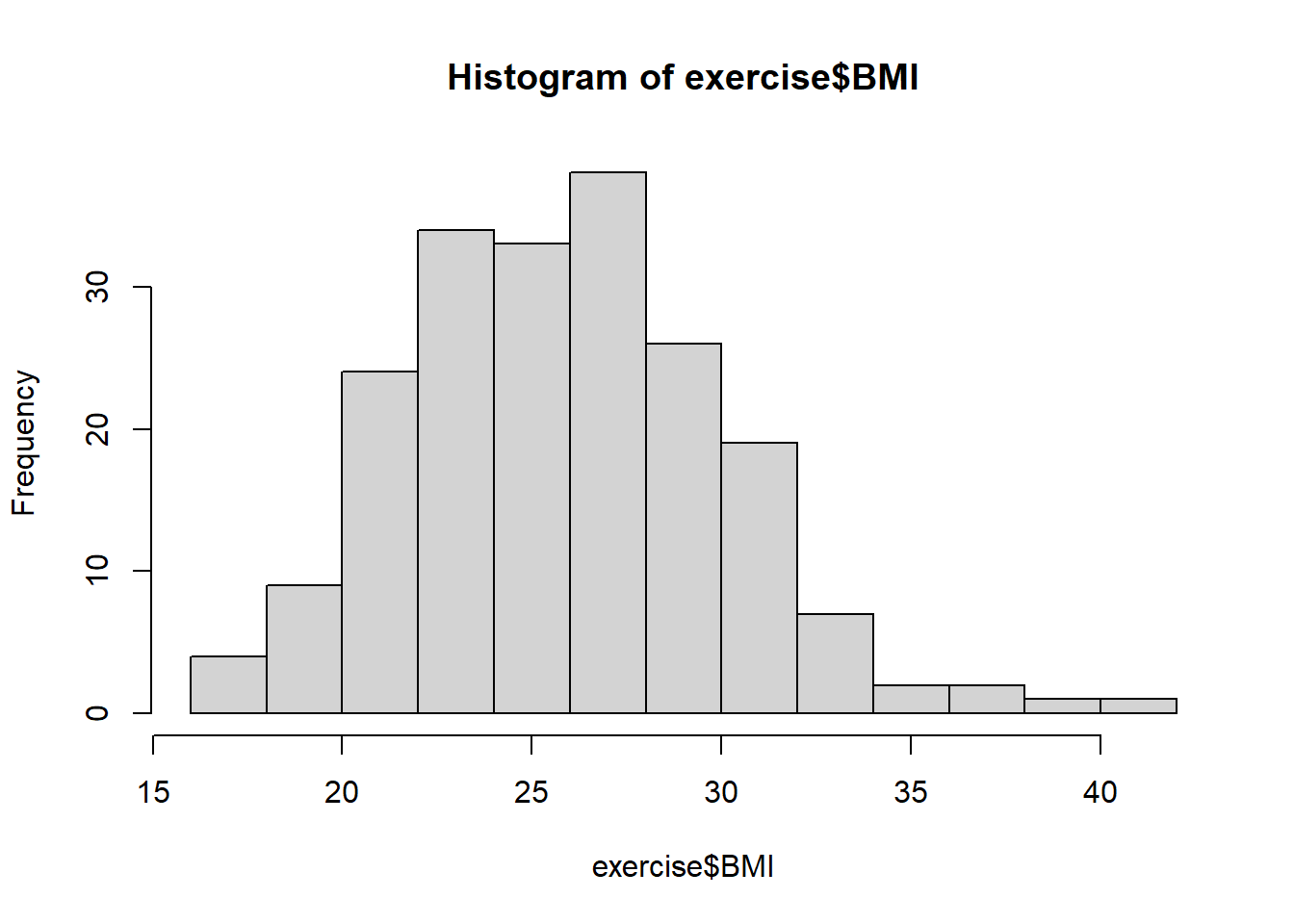
hist(exercise$BMI)
# Split into training and testing -----------------------------------------# Choose your own proportion for the split!set.seed(1234)ex_split <-initial_split(exercise, prop =0.7)ex_train <-training(ex_split)ex_test <-testing(ex_split)# Create cross validation folds# Choose how many splits and how many repeats!ex_folds <-vfold_cv(ex_train, v =10, repeats =2)# Build a recipe ----------------------------------------------------------# Use the `recipe()` function and the `step_*() functions`ex_recipe <-recipe(SAE ~ ., data = ex_train) |>step_dummy(Treatment:VE_Cardio) |>step_normalize(all_numeric())# create a workflow and add the recipeex_wf <-workflow() |>add_recipe(ex_recipe)
Exercise 2: Lasso regression
Specify the model using logistic_reg().
Tune the hyperparameter.
Choose the best value and fit the final model.
Evaluate the model performance.
Solution
# Specify the model -------------------------------------------------------# use the `logistic_reg` and `set_engine` functionsex_lasso_tune_spec <-logistic_reg(penalty =tune(), mixture =1) |>set_engine("glmnet")# Tune the model ----------------------------------------------------------# Fit lots of values using `tune_grid()`ex_lasso_grid <-tune_grid(add_model(ex_wf, ex_lasso_tune_spec),resamples = ex_folds,grid =grid_regular(penalty(), levels =50))# Choose the best value using `select_best()`ex_lasso_highest_roc_auc <- ex_lasso_grid |>select_best(metric ="roc_auc")# Fit the final model -----------------------------------------------------# use the `finalize_workflow` function and `add_model`ex_final_lasso <-finalize_workflow(add_model(ex_wf, ex_lasso_tune_spec), ex_lasso_highest_roc_auc)# Model evaluation --------------------------------------------------------# use `last_fit()` and `collect_metrics()`last_fit(ex_final_lasso, ex_split) |>collect_metrics()
Specify a support vector machine using svm_rbf() (or one of the other svm_* functions if you’re feeling confident!)
Tune the cost() hyperparameter using the cross-validation folds.
Fit the final model and evaluate it.
Look at some other evaluation metrics.
Solution
# Specify model -----------------------------------------------------------ex_svm_tune_spec <-svm_rbf(cost =tune()) |>set_engine("kernlab") |>set_mode("classification")# Tune hyperparameters ----------------------------------------------------# Fit lots of values using `tune_grid()`ex_svm_grid <-tune_grid(add_model(ex_wf, ex_svm_tune_spec),resamples = ex_folds,grid =grid_regular(cost(), levels =20))# Fit model ---------------------------------------------------------------ex_svm_highest_roc_auc <- ex_svm_grid |>select_best(metric ="roc_auc")ex_final_svm <-finalize_workflow(add_model(ex_wf, ex_svm_tune_spec), ex_svm_highest_roc_auc)# Evaluate ----------------------------------------------------------------# select a different metric set using `metric_set` if you want!last_fit(ex_final_svm, ex_split,metrics =metric_set(roc_auc, accuracy, f_meas)) |>collect_metrics()