Scraping London Marathon data with {rvest}
{rvest} is an R package within the {tidyverse} which helps you scrape data from web pages. This blog post will showcase an example of scraping data from Wikipedia on London Marathon races and winners.
March 16, 2023
There are lots of ways to get data into R: reading from local files or URLs, R packages containing data, using packages that wrap APIs, to name a few. But sometimes, none of those are an option. Let’s say you want get a table of data from a website (that doesn’t provide API access). You could copy and paste it into a spreadsheet, re-format it manually, and then read it into R. But (to me, at least) that sounds horribly tedious…
That’s where {rvest} comes in. {rvest} is an R package within the {tidyverse} which helps you scrape data from web pages. This blog post will showcase an example of scraping data from Wikipedia on London Marathon races and winners. By the end, you should be ready to scrape some data of your own!

Image: giphy.com
A note on web-scraping: many websites have a
robots.txtfile which contains instructions for bots that tell them which webpages they can and cannot access. The relies on voluntary compliance, so please check a websitesrobots.txtfile before you jump straight to web-scraping. If you’re scraping multiple pages, you can use the {polite} package to make sure you respect therobots.txtfile.
Loading the R packages
For the process of scraping the London Marathon data from Wikipedia, we need five R packages: {rvest} for web-scraping, {dplyr} for manipulating the scraped data, {lubridate} and {chron} for working with the time data (optional depending on your use case), and {readr} to save the data for re-use later.
| |
Scraping the data
Now let’s actually get the data! The key function in {rvest} is read_html() which does what it says on the tin and reads in the HTML code used on the site you pass in as the first argument:
| |
The initial output doesn’t look particularly nice:
| |
Fortunately, {rvest} has some nice functions to parse this output for you, and get the elements of the site that you’re actually interested in.
| |
Here, I’ve passed in ".wikitable.sortable" to html_elements(). Here, html_elements() grabs all the elements which have ".wikitable.sortable" as their CSS class. I determined that ".wikitable.sortable" was the class I was looking for by using Inspect on the Wikipedia page (use the Ctrl + Shift + I shortcut). The html_table() then tidies this up even further, and returns a list of tibbles where each list entry is a different table from the Wikipedia page.
Tidying it up
The first four tibbles contain information on the four categories of racing at London Marathon, and the fifth contains a summary table by country. Since the fifth table data can be captured from the first four, and it’s in a completely different format, I decided to discard it. Now what I want to do is combine the remaining four tibbles into a single tibble, with an additional column determining which race the data relates to.
First things first, let’s decide what the names of the categories are. I could have grabbed this information from the Wikipedia itself, as each table has a section header. However, the title’s weren’t quite what I was looking for and I would have had to recode them anyway, so I decided to just directly recode the list of tibbles. The categories can then be set as the names of the list items.
| |
Fortunately for me, the column names in the four remaining tables already all have the same names. This meant I could take advantage of bind_rows() from {dplyr} to collapse the list into a single tibble. Setting .id = "Category" creates a new column in the tibble called Category which contains the list name as a variable. I also dropped the Notes free text column.
| |
The last bit of processing to do is deal with the time data. I decided to rename the column to Time, and convert it to a formal time object using the chron() function from {chron}. The Year column was slightly trickier than it appeared at first glance - some of the entries had a footnote marker next to the year - so as.numeric() doesn’t work out of the box, it needed a little regex first!
| |
Finally, we can save the data, either as a CSV or an RDS file to make it easier to work with it later, and to avoid repeatedly scraping the same data.
| |
Repeating the process
I decided to repeat the process for data on number of London Marathon participants, and how much charity money was raised, as this might pose some interesting questions for further analysis. You can see here, that the process is quite similar:
| |
Working with the data
Now, we can work with the scraped data in the same way we’d work with any other (cleaned up) data in R! Including making plots!
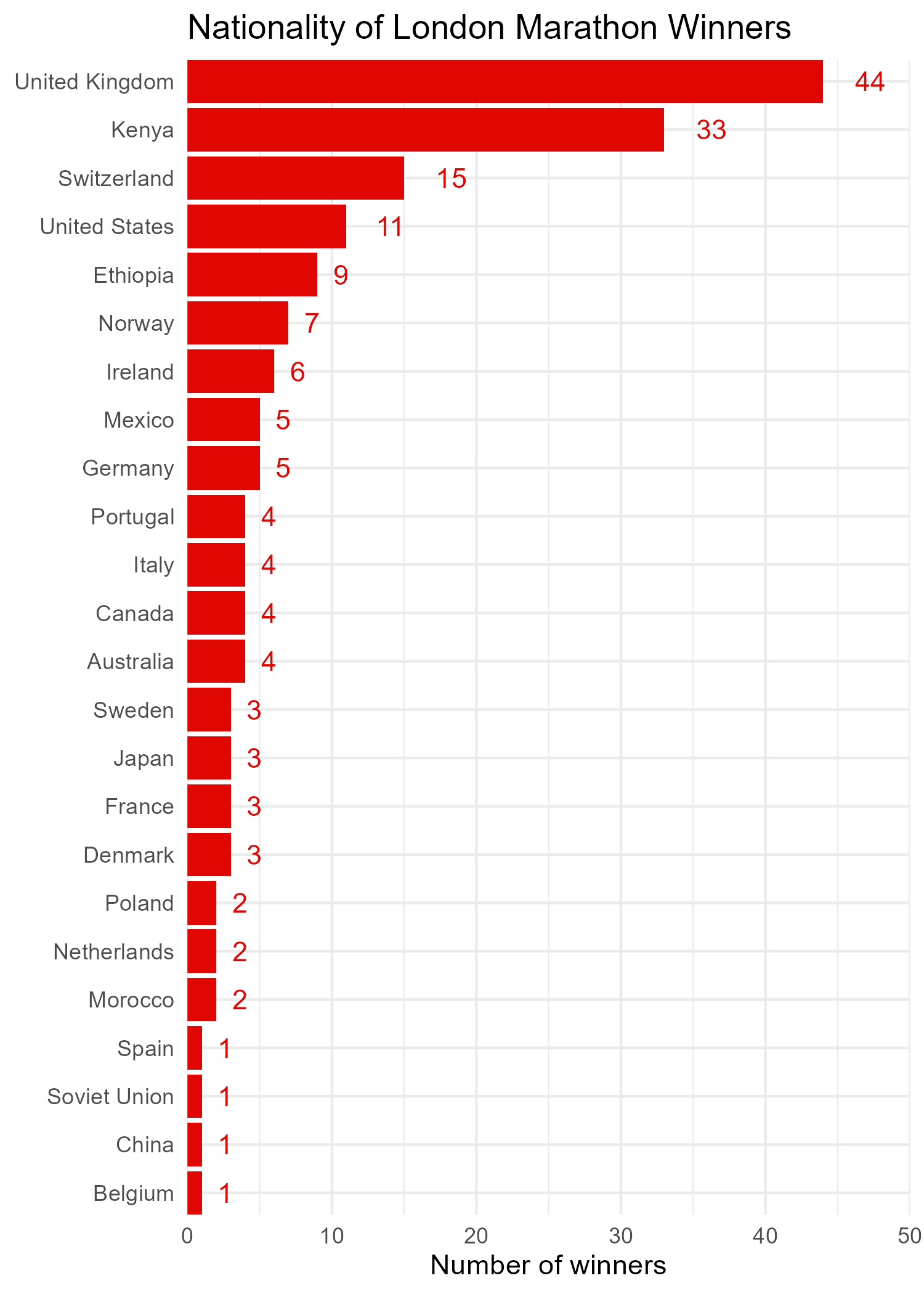
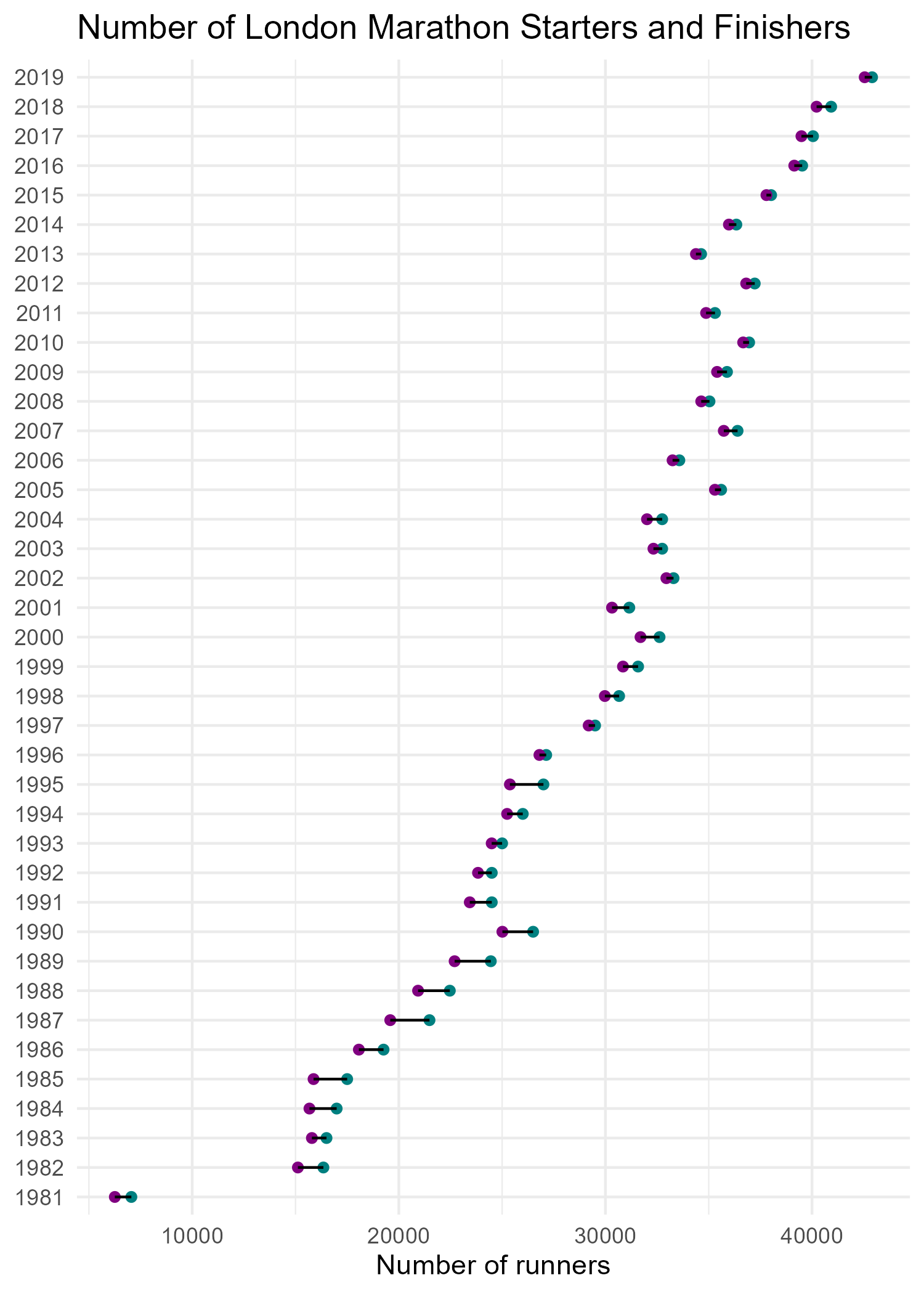
Code for the plots can be found on GitHub.
If you’re only interested in working with the data, and less in the web scraping, you can load the data directly from the {LondonMarathon} R package with:
| |
Final thoughts
I hope this blog post has convinced you that scraping data from a website does need to be as difficult as it sounds, and that it’s a better option that copying and pasting! The code, data, data dictionary, and a few exploratory plots can be found on GitHub.
If you need to interact with the website you’re scraping in some way e.g. inputting log in details, or clicking on buttons to select data, you’ll likely find {RSelenium} a very useful package! This blog post from Andrew Brooks on how to use {RSelenium} for web scraping gives a short introduction.
The background photo in the cover image of this blog post is from Benjamin Davies on Unsplash.
For attribution, please cite this work as:
Scraping London Marathon data with {rvest}.
Nicola Rennie. March 16, 2023.
nrennie.rbind.io/blog/web-scraping-rvest-london-marathon
BibLaTeX Citation
@online{rennie2023,
author = {Nicola Rennie},
title = {Scraping London Marathon data with {rvest}},
date = {2023-03-16},
url = {https://nrennie.rbind.io/blog/web-scraping-rvest-london-marathon}
}
Licence: creativecommons.org/licenses/by/4.0